Climate Change Impact Analysis#
To highlight the impacts of climate change on our catchment we can calculate a set of indicators frequently used in climate impact studies. In this notebook we will…
…calculate meterological and hydrological statistics for our modelling results,
…plot these climate change indcators interactive applications to explore the impacts.
We start by reading paths and MATILDA outputs again.
Show code cell source
from tools.helpers import pickle_to_dict, parquet_to_dict
import configparser
# read output directory from config.ini file
config = configparser.ConfigParser()
config.read('config.ini')
dir_output = config['FILE_SETTINGS']['DIR_OUTPUT']
print("Importing MATILDA scenarios...")
# For size:
matilda_scenarios = parquet_to_dict(f"{dir_output}cmip6/adjusted/matilda_scenarios_parquet")
# For speed:
# matilda_scenarios = pickle_to_dict(f"{dir_output}cmip6/adjusted/matilda_scenarios.pickle")
Importing MATILDA scenarios...
Reading parquet files: 100%|██████████████████████| 2/2 [00:07<00:00, 3.57s/it]
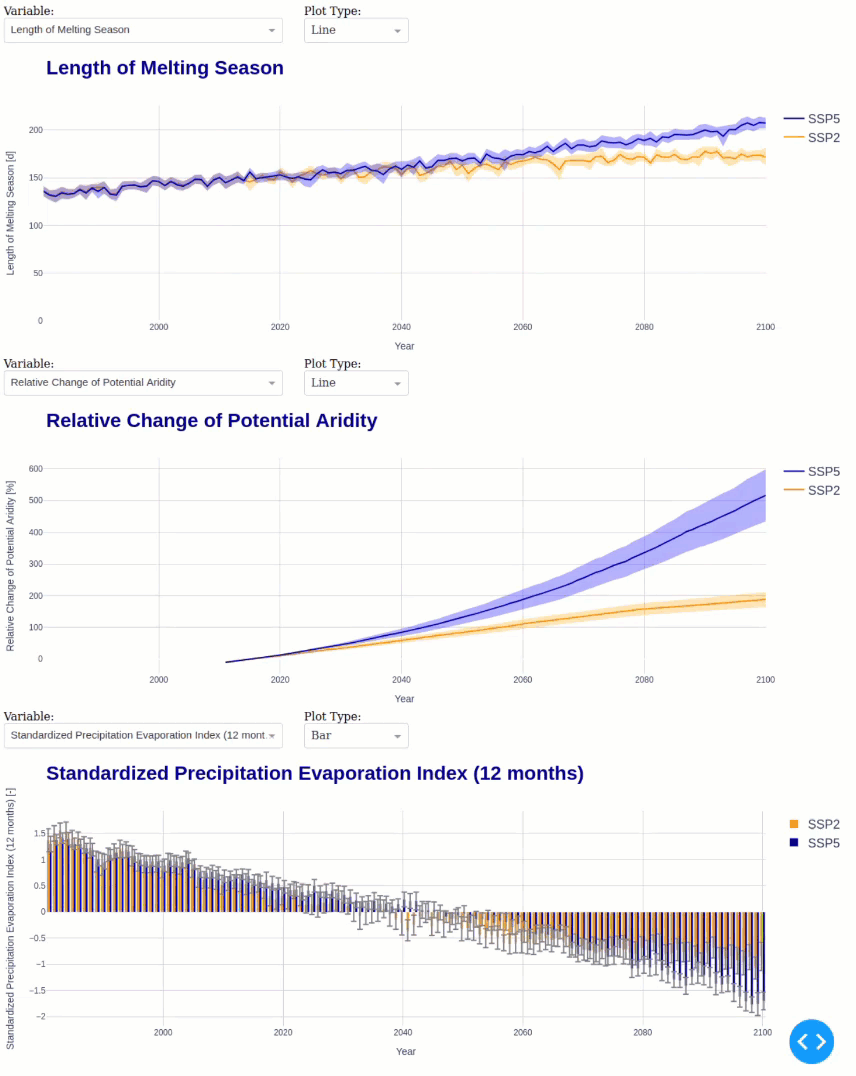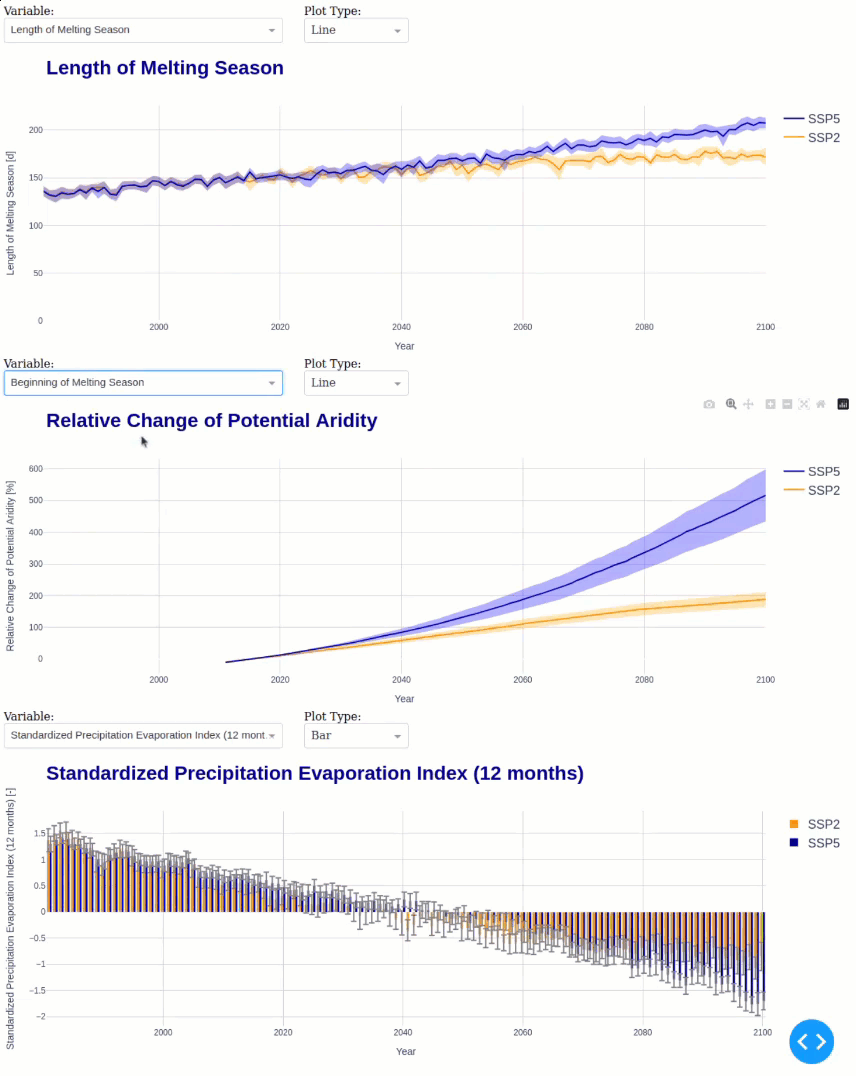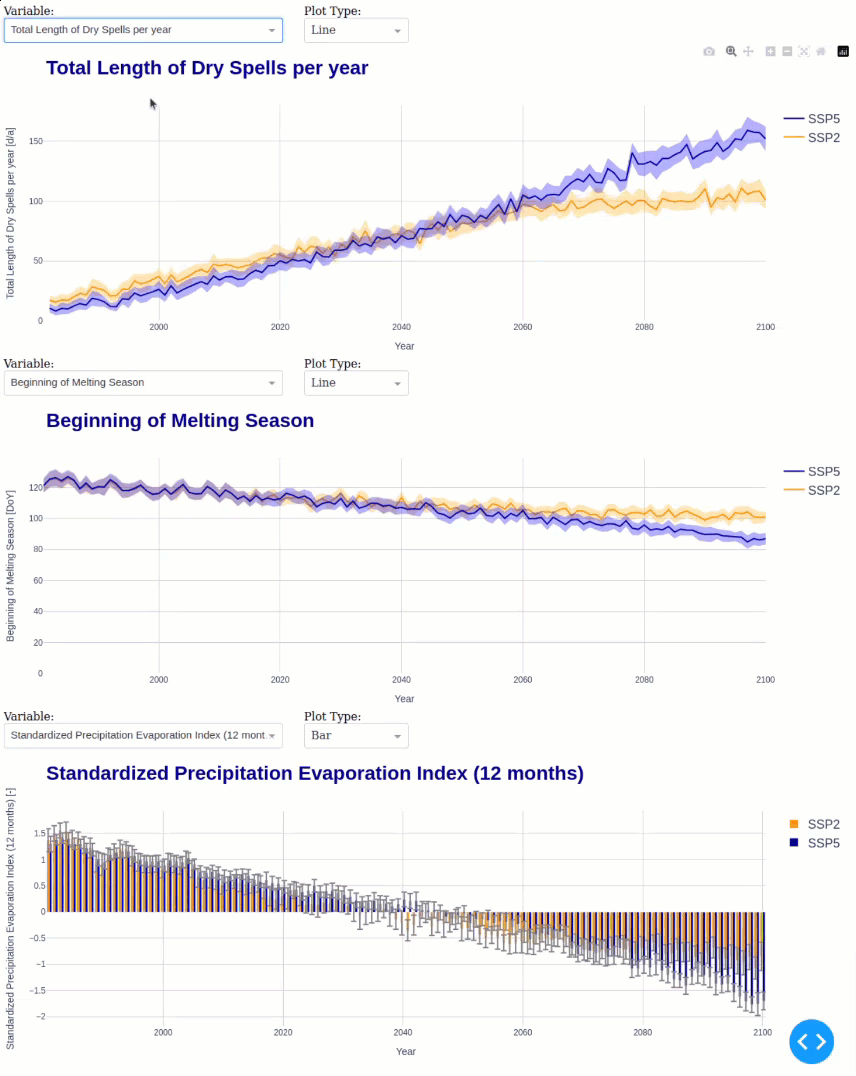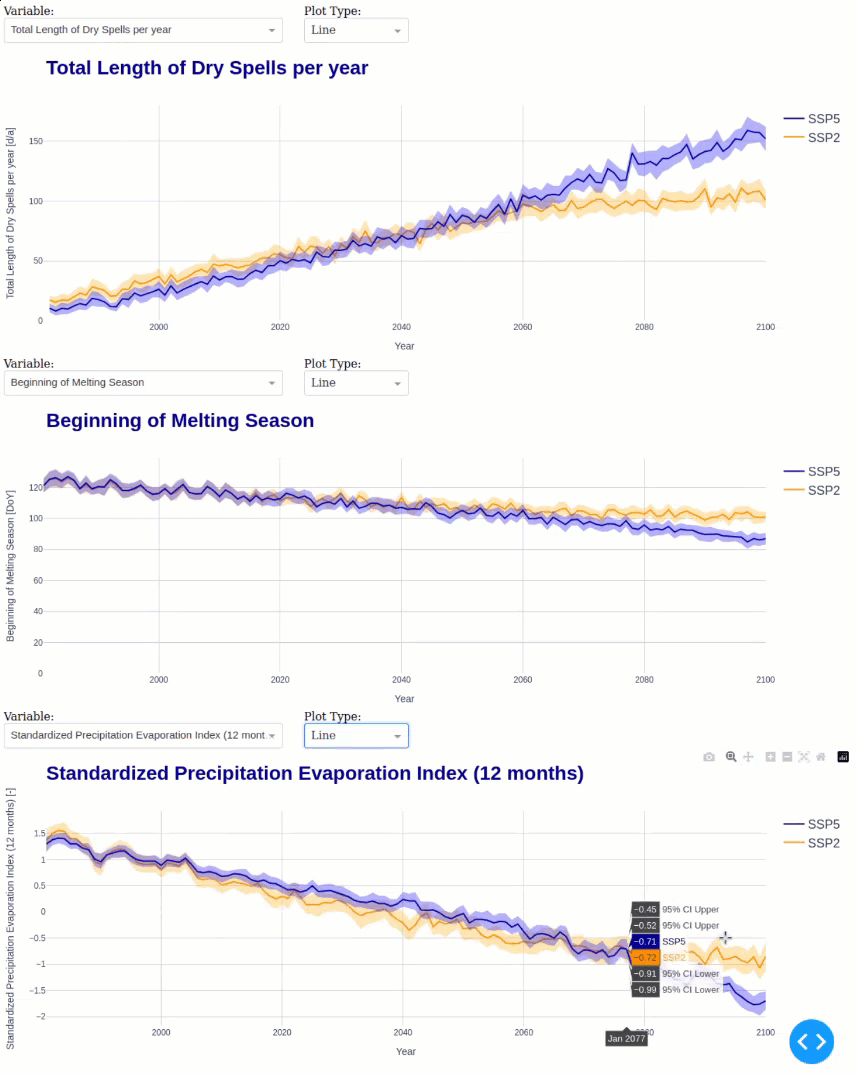
This module calculates the following statistics for all ensemble members in annual resolution:
Month with minimum/maximum precipitation
Timing of Peak Runoff
Begin, End, and Length of the melting season
Potential and Actual Aridity
Total Length of Dry Spells
Average Length and Frequency of Low Flow Events
Average Length and Frequency of High Flow Events
5th Percentile of Total Runoff
50th Percentile of Total Runoff
95th Percentile of Total Runoff
Climatec Water Balance
SPI (Standardized Precipitation Index) and SPEI (Standardized Precipitation Evapotranspiration Index) for 1, 3, 6, 12, and 24 months
For details on these metrics check the source code.
Show code cell source
from tools.indicators import cc_indicators
from tqdm import tqdm
import pandas as pd
from tools.helpers import dict_to_pickle, dict_to_parquet
def calculate_indicators(dic, **kwargs):
"""
Calculate climate change indicators for all scenarios and models.
Parameters
----------
dic : dict
Dictionary containing MATILDA outputs for all scenarios and models.
**kwargs : optional
Optional keyword arguments to be passed to the cc_indicators() function.
Returns
-------
dict
Dictionary with the same structure as the input but containing climate change indicators in annual resolution.
"""
# Create an empty dictionary to store the outputs
out_dict = {}
# Loop over the scenarios with progress bar
for scenario in dic.keys():
model_dict = {} # Create an empty dictionary to store the model outputs
# Loop over the models with progress bar
for model in tqdm(dic[scenario].keys(), desc=scenario):
# Get the dataframe for the current scenario and model
df = dic[scenario][model]['model_output']
# Run the indicator function
indicators = cc_indicators(df, **kwargs)
# Store indicator time series in the model dictionary
model_dict[model] = indicators
# Store the model dictionary in the scenario dictionary
out_dict[scenario] = model_dict
return out_dict
print("Calculating Climate Change Indicators...")
matilda_indicators = calculate_indicators(matilda_scenarios)
print("Writing Indicators To File...")
dict_to_parquet(matilda_indicators, f"{dir_output}cmip6/adjusted/matilda_indicators_parquet")
# dict_to_pickle(matilda_indicators, f"{dir_output}cmip6/adjusted/matilda_indicators_pickle")
Calculating Climate Change Indicators...
SSP2: 100%|█████████████████████████████████████| 31/31 [01:07<00:00, 2.17s/it]
SSP5: 100%|█████████████████████████████████████| 31/31 [00:51<00:00, 1.68s/it]
Writing Indicators To File...
Writing parquet files: 100%|██████████████████████| 2/2 [00:04<00:00, 2.06s/it]
Similar to the last notebook we write a function to create customs dataframes for individual indicators across all ensemble members…
Show code cell source
def custom_df_indicators(dic, scenario, var):
"""
Takes a dictionary of climate change indicators and returns a combined dataframe of a specific variable for
a given scenario.
Parameters
----------
dic : dict
Dictionary containing the outputs of calculate_indicators() for different scenarios and models.
scenario : str
Name of the selected scenario.
var : str
Name of the variable to extract from the DataFrame.
Returns
-------
pandas.DataFrame
A DataFrame containing the selected variable from different models within the specified scenario.
Raises
------
ValueError
If the provided variable is not one of the function outputs.
"""
out_cols = ['max_prec_month', 'min_prec_month',
'peak_day',
'melt_season_start', 'melt_season_end', 'melt_season_length',
'actual_aridity', 'potential_aridity',
'dry_spell_days',
'qlf_freq', 'qlf_dur', 'qhf_freq', 'qhf_dur',
'clim_water_balance', 'spi1', 'spei1', 'spi3', 'spei3',
'spi6', 'spei6', 'spi12', 'spei12', 'spi24', 'spei24']
if var not in out_cols:
raise ValueError("var needs to be one of the following strings: " +
str([i for i in out_cols]))
# Create an empty list to store the dataframes
dfs = []
# Loop over the models in the selected scenario
for model in dic[scenario].keys():
# Get the dataframe for the current model
df = dic[scenario][model]
# Append the dataframe to the list of dataframes
dfs.append(df[var])
# Concatenate the dataframes into a single dataframe
combined_df = pd.concat(dfs, axis=1)
# Set the column names of the combined dataframe to the model names
combined_df.columns = dic[scenario].keys()
return combined_df
… and write a plot function for a single plot.
Show code cell source
from tools.indicators import indicator_vars
import plotly.graph_objects as go
import numpy as np
def confidence_interval(df):
"""
Calculate the mean and 95% confidence interval for each row in a dataframe.
Parameters:
-----------
df (pandas.DataFrame): The input dataframe.
Returns:
--------
pandas.DataFrame: A dataframe with the mean and confidence intervals for each row.
"""
mean = df.mean(axis=1)
std = df.std(axis=1)
count = df.count(axis=1)
ci = 1.96 * std / np.sqrt(count)
ci_lower = mean - ci
ci_upper = mean + ci
df_ci = pd.DataFrame({'mean': mean, 'ci_lower': ci_lower, 'ci_upper': ci_upper})
return df_ci
def plot_ci_indicators(var, dic, plot_type='line', show=False):
"""
A function to plot multi-model mean and confidence intervals of a given variable for two different scenarios.
Parameters:
-----------
var: str
The variable to plot.
dic: dict, optional (default=matilda_scenarios)
A dictionary containing the scenarios as keys and the dataframes as values.
plot_type: str, optional (default='line')
Whether the plot should be a line or a bar plot.
show: bool, optional (default=False)
Whether to show the resulting plot or not.
Returns:
--------
go.Figure
A plotly figure object containing the mean and confidence intervals for the given variable in the two selected scenarios.
"""
if var is None:
var = 'total_runoff' # Default if nothing selected
# SSP2
df1 = custom_df_indicators(dic, scenario='SSP2', var=var)
df1_ci = confidence_interval(df1)
# SSP5
df2 = custom_df_indicators(dic, scenario='SSP5', var=var)
df2_ci = confidence_interval(df2)
if plot_type == 'line':
fig = go.Figure([
# SSP2
go.Scatter(
name='SSP2',
x=df1_ci.index,
y=round(df1_ci['mean'], 2),
mode='lines',
line=dict(color='darkorange'),
),
go.Scatter(
name='95% CI Upper',
x=df1_ci.index,
y=round(df1_ci['ci_upper'], 2),
mode='lines',
marker=dict(color='#444'),
line=dict(width=0),
showlegend=False
),
go.Scatter(
name='95% CI Lower',
x=df1_ci.index,
y=round(df1_ci['ci_lower'], 2),
marker=dict(color='#444'),
line=dict(width=0),
mode='lines',
fillcolor='rgba(255, 165, 0, 0.3)',
fill='tonexty',
showlegend=False
),
# SSP5
go.Scatter(
name='SSP5',
x=df2_ci.index,
y=round(df2_ci['mean'], 2),
mode='lines',
line=dict(color='darkblue'),
),
go.Scatter(
name='95% CI Upper',
x=df2_ci.index,
y=round(df2_ci['ci_upper'], 2),
mode='lines',
marker=dict(color='#444'),
line=dict(width=0),
showlegend=False
),
go.Scatter(
name='95% CI Lower',
x=df2_ci.index,
y=round(df2_ci['ci_lower'], 2),
marker=dict(color='#444'),
line=dict(width=0),
mode='lines',
fillcolor='rgba(0, 0, 255, 0.3)',
fill='tonexty',
showlegend=False
)
])
elif plot_type == 'bar':
fig = go.Figure([
# SSP2
go.Bar(
name='SSP2',
x=df1_ci.index,
y=round(df1_ci['mean'], 2),
marker=dict(color='darkorange'),
error_y=dict(
type='data',
symmetric=False,
array=round(df1_ci['mean'] - df1_ci['ci_lower'], 2),
arrayminus=round(df1_ci['ci_upper'] - df1_ci['mean'], 2),
color='grey'
)
),
# SSP5
go.Bar(
name='SSP5',
x=df2_ci.index,
y=round(df2_ci['mean'], 2),
marker=dict(color='darkblue'),
error_y=dict(
type='data',
symmetric=False,
array=round(df2_ci['mean'] - df2_ci['ci_lower'], 2),
arrayminus=round(df2_ci['ci_upper'] - df2_ci['mean'], 2),
color='grey'
)
)
])
else:
raise ValueError("Invalid property specified for 'plot_type'. Choose either 'line' or 'bar'")
fig.update_layout(
xaxis_title='Year',
yaxis_title=indicator_vars[var][0] + ' [' + indicator_vars[var][1] + ']',
title={'text': '<b>' + indicator_vars[var][0] + '</b>', 'font': {'size': 28, 'color': 'darkblue', 'family': 'Arial'}},
legend={'font': {'size': 18, 'family': 'Arial'}},
hovermode='x',
plot_bgcolor='rgba(255, 255, 255, 1)', # Set the background color to white
margin=dict(l=10, r=10, t=90, b=10), # Adjust the margins to remove space around the plot
xaxis=dict(gridcolor='lightgrey'), # set the grid color of x-axis to lightgrey
yaxis=dict(gridcolor='lightgrey'), # set the grid color of y-axis to lightgrey
)
fig.update_yaxes(rangemode='tozero')
# show figure
if show:
fig.show()
else:
return fig
plot_ci_indicators(var = 'potential_aridity', dic = matilda_indicators, plot_type='line', show=True)
Finally, we can launch the interactive Dash app to analyze the climate change impacts.
Show code cell source
import dash
from dash import dcc
from dash import html
from dash.dependencies import Input, Output
import plotly.io as pio
pio.renderers.default = "browser"
app = dash.Dash()
# Create default variables for every figure
default_vars = ['peak_day', 'melt_season_length', 'potential_aridity', 'spei12']
default_types = ['line', 'line', 'line', 'bar']
default_vars = ['melt_season_length', 'potential_aridity', 'spei12']
default_types = ['line', 'line', 'bar']
# Create separate callback functions for each dropdown menu and graph combination
for i in range(3):
@app.callback(
Output(f'line-plot-{i}', 'figure'),
Input(f'arg-dropdown-{i}', 'value'),
Input(f'type-dropdown-{i}', 'value')
)
def update_figure(selected_arg, selected_type, i=i):
fig = plot_ci_indicators(selected_arg, matilda_indicators, selected_type)
return fig
# Define the dropdown menus and figures
dropdowns_and_figures = []
for i in range(3):
arg_dropdown = dcc.Dropdown(
id=f'arg-dropdown-{i}',
options=[{'label': indicator_vars[var][0], 'value': var} for var in indicator_vars.keys()],
value=default_vars[i],
clearable=False,
style={'width': '400px', 'fontFamily': 'Arial', 'fontSize': 15}
)
type_dropdown = dcc.Dropdown(
id=f'type-dropdown-{i}',
options=[{'label': lab, 'value': val} for lab, val in [('Line', 'line'), ('Bar', 'bar')]],
value=default_types[i],
clearable=False,
style={'width': '150px'}
)
dropdowns_and_figures.append(
html.Div([
html.Div([
html.Label("Variable:"),
arg_dropdown,
], style={'display': 'inline-block', 'margin-right': '30px'}),
html.Div([
html.Label("Plot Type:"),
type_dropdown,
], style={'display': 'inline-block'}),
dcc.Graph(id=f'line-plot-{i}'),
])
)
# Combine the dropdown menus and figures into a single layout
app.layout = html.Div(dropdowns_and_figures)
# Run the app
app.run_server(debug=True, use_reloader=False, port=8051) # Turn off reloader inside Jupyter